Web as a Bureaucratic Machine
Rest Assured that REST Works

Rest Assured that REST Works

There was a time when we didn’t have the global, planetary network we now call the World Wide Web (web for short). Despite the fact that, technologically speaking, we could’ve had the web much sooner (thanks of course to the existence of the well entrenched TCP/IP network transfer protocol), the useful communication protocol hasn’t been invented until Tim Berners Lee proposed it on November 12, 1990.
The reasons for that delay could be manifold, and certainly they are debatable, but undoubtedly one of the main reasons was the unnecessary (in hindsight) level of engineering perfectionism that was brought into preliminary discussions around any concept of a global computer network. Such debilitating analysis paralisis got removed only once the controversial ‘worse is better’ principle was embraced. Applying this principle cleared up the way toward the web as we know it, thanks to the amazing single-handed efforts by Tim Berners Lee. Previous attempts at architecting, designing and implementing world wide web were unsuccessful because, among other reasons, participants could not reach a consensus on how to deal with broken links; Mr. Berners Lee bypassed that conundrum by choosing not to care about broken links. Worse is better in action.
Communication Protocol
Computers plugged into the network must communicate via some protocol. In the case of the world wide web, that protocol is Hypertext Transfer Protocol (HTTP). This communication protocol gives us the fundamental alphabet that is then used for building up a vocabulary upon which various events and representations take place on and around the planetary web.
It would be normal then to expect that most, if not all of the resources existing on the web today are built around this protocol. That, sadly, is rarely the case. Instead of utilizing this incredibly powerful and efficient communication protocol, most web sites in existence today use this protocol as a mere delivery channel. This delivery channel gets used for tunnelling between connected computers, while carrying the huge overhead of home-grown communication protocols that are then being used as a way select few participants talk to each other.
Why the Overhead?
It is shocking to learn about the existence of such enormous overhead. Not only is it insanely impractical and unwieldy to be inventing one’s own, Mickey Mouse communication protocol when the global, robust de facto protocol has already been in place for more than two decades, it is also an extremely brittle thing to do. Plus, it is very costly to expect to involve other interested parties to join the conversation, because they would have to master the proprietary communication protocols beforehand. So why are we doing it then?
The answer is quite simple: HTTP is not that easy to grasp. Don’t believe me? Have a look at this diagram:

The above diagram depicts all HTTP status codes. As it stands now, it is a state machine.
Taming the HTTP Complexity
Let’s now try to break this complex picture down into more digestible units, in the hopes of being able to better internalize and digest this ‘mysterious’ communication protocol. In a nutshell, HTTP could be broken down into seven relatively isolated areas of concern:
Validation & Authentication
Content negotiation
Conditional requests
Existence and redirection
PUT/POST
DELETE
Body
Each of the above seven areas of concern could be further viewed as a constituent sub-state machine (or is it state sub-machine)? Commonly accepted wisdom teaches the divide and conquer approach, so let’s look into each individual digram for each of these subsystems a bit closer. Let’s begin with the Validation & Authentication subsystem:

Starting from the bottom (which is the entry point for the HTTP Request), we see that the protocol evaluates the request on number of points. Each point of evaluation either passes (true) or fails (false). In case the request fails, an appropriate status code gets assigned to the HTTP Response which then gets shipped back to the requesting client.
We see from the above diagram that, with regard to the validation & authentication domain, the machine can go through eleven possible states. These states are pretty much self explanatory, so I don’t think we have to dive any deeper into those details here.
Let’s move to the Content negotiation area:
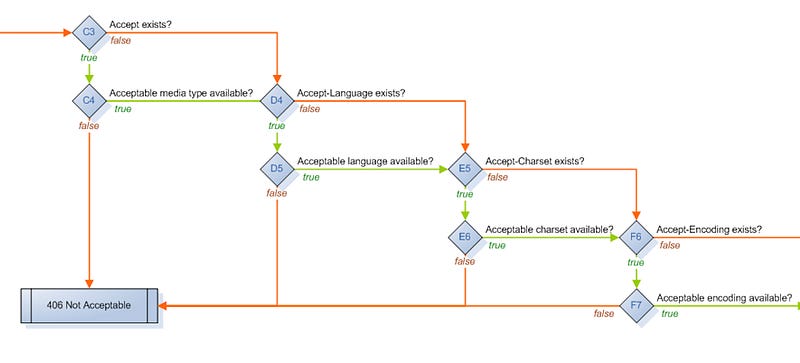
From the above diagram we see how HTTP negotiates acceptable content, in terms of the media type, language, charset, encoding. This area appears plain and straightforward, but only to the untrained eye. There is more here then what bubbles to the surface. Suffice it to say that various browser implementation may treat the negotiation process differently, and may produce different, often times surprising results. Understanding the issues surrounding this important area of concern, especially in the context of browser cacheing etc., distinguishes qualified web developers from the wannabes.
Next, let’s look into conditional requests:

Conditional requests negotiate with the client browser whether the local cache had expired or not. Notice the role of etags (or, entity tags), which although optional, can aide this sensitive negotiation process. Has the resource been modified since the last time it was represented to the client? If the resource has been modified since certain time, is the format of that time stamp even valid? And so on. Answers to these kinds of questions are vitally critical to ensure that the resource in question is not deceiving enquiring clients who are interrogating it/acting upon it.
Existence and redirection:

Negotiating the existence of a resource is extremely critical in order to ensure whether intended action should be allowed. More detailed discussion about this area of concern is definitely needed here, however its scope exceeds the bounds of this article.
PUT/POST:

This area deals with negotiations pertaining to non-idempotent actions implied by HTTP Request. If resource doesn’t exist, then if the HTTP Request is POST, it should result in the creation of said resource.
DELETE:

Delete is quite straightforward, as can be seen from the above diagram.
Finally, the Body:

It is hopefully easier now to see from the above diagrams that HTTP is a well thought out finite state machine that enables us to deal with any and all possible events that may transpire on the web. As such, this machine is all we need in order to construct a fully operational web site (i.e. a collection of useful and interesting web resources).